Work the way you think.
Your decision loop, enhanced and preserved. AI for research velocity.
IRIS is the operating system for institutional investment research.
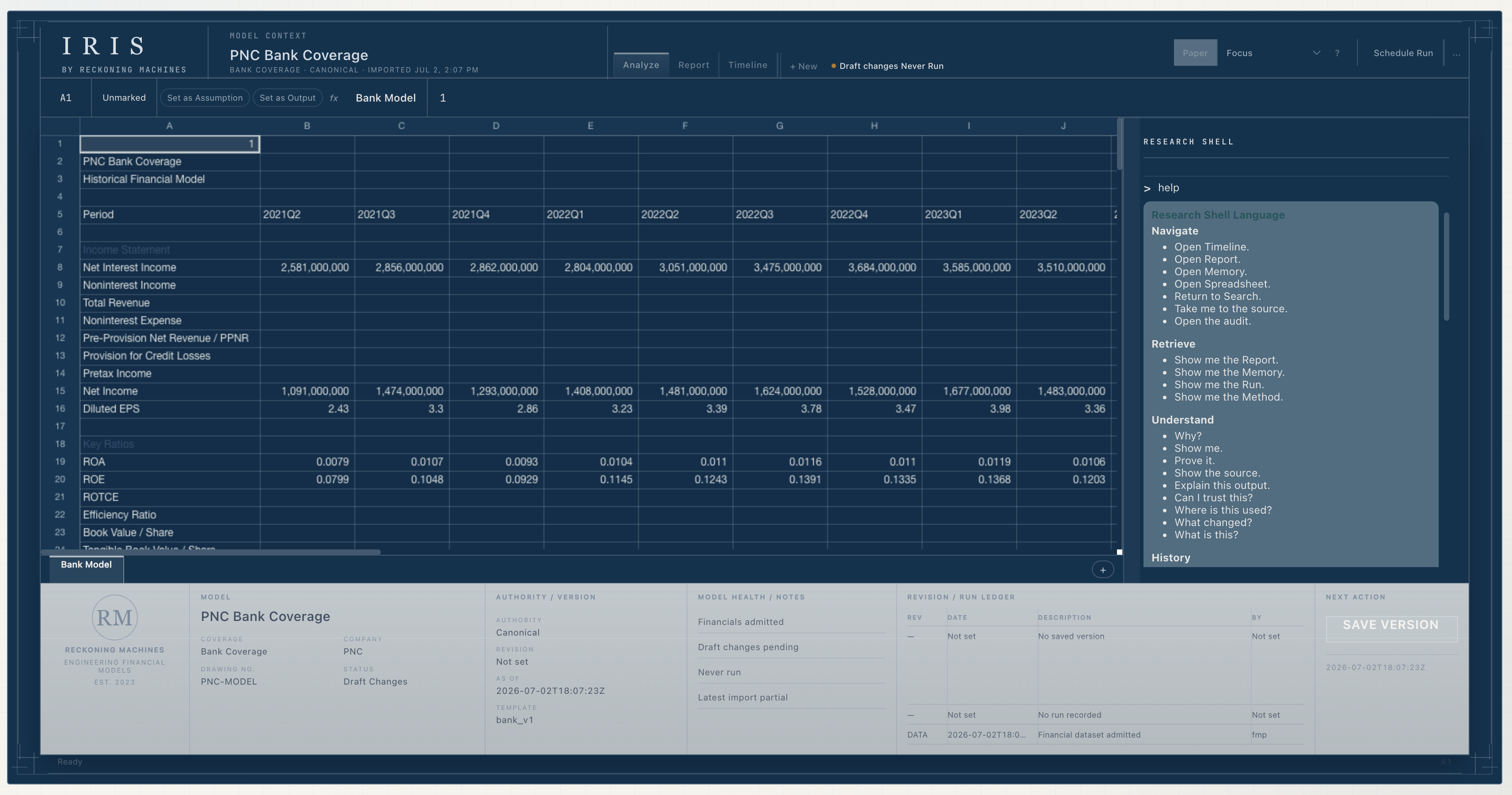
Figure 1 The Research Velocity Flywheel The operating model behind IRIS.
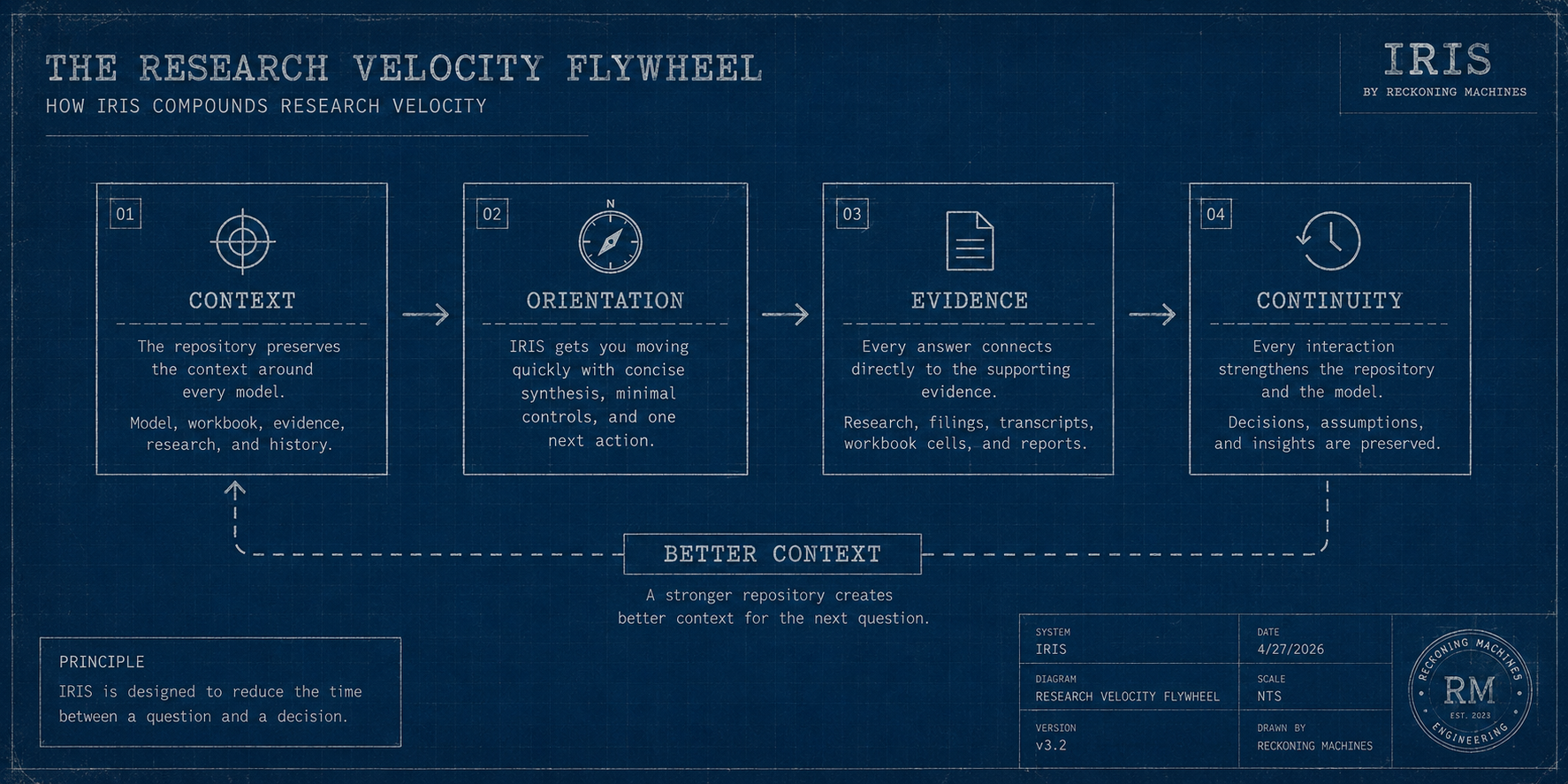
The repository already knows the model, workbook, evidence, research, and history. You start with context instead of rebuilding it.
IRIS gets you moving quickly with concise synthesis, minimal controls, and one next action. Less time navigating. More time thinking.
Every answer connects directly to supporting evidence. Research is one click away, not another search.
Every governed output strengthens the repository. Today's work becomes tomorrow's context.
A Point of View
Ending investment amnesia.
AI answers questions.
IRIS preserves how your organization thinks.
Research compounds.
Institutional knowledge compounds.
Every decision strengthens the next one.
Memory is the multiplier.
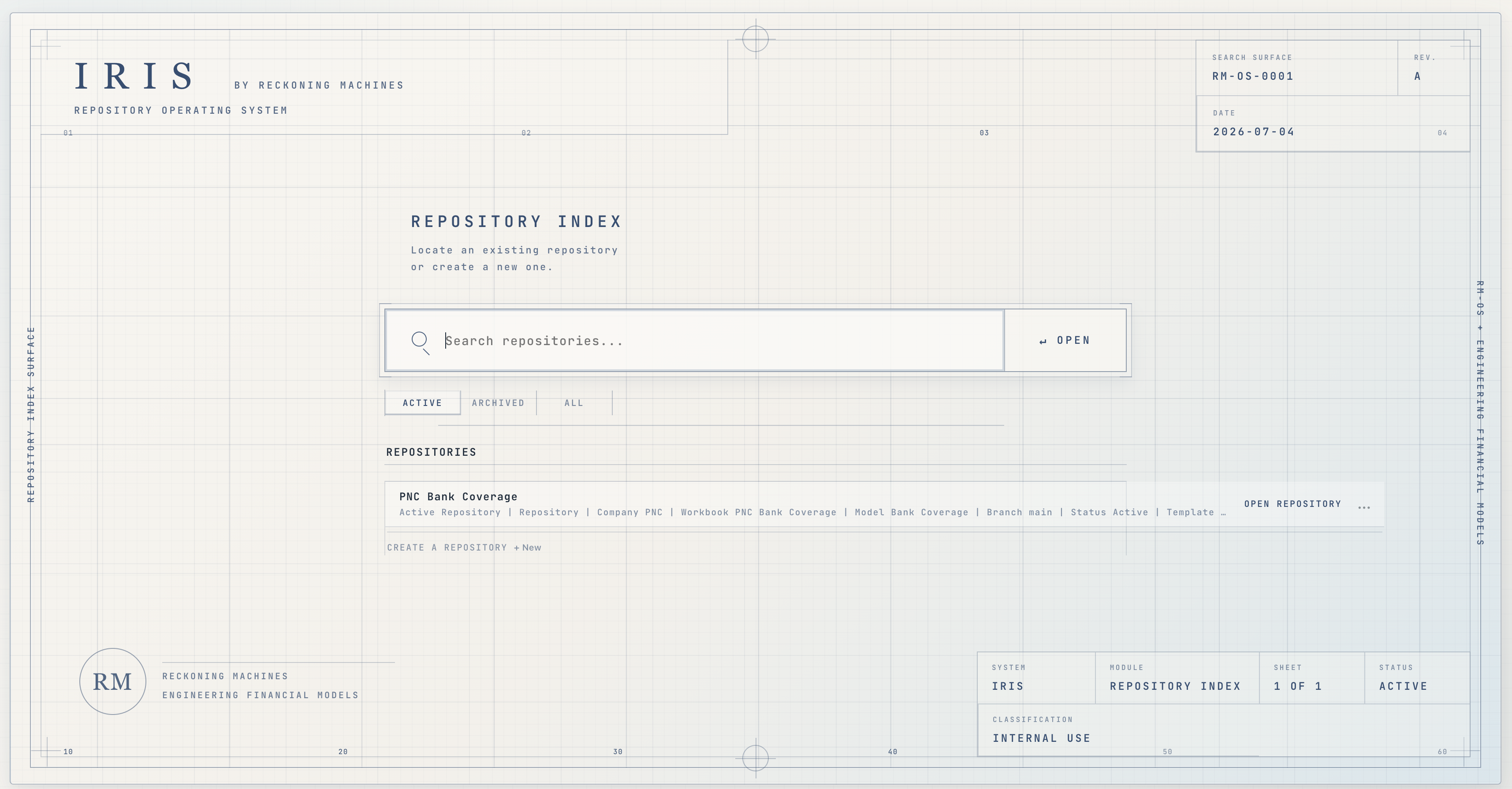
Start with the model.
Search is the front door. Open a company, model, question, or research surface without managing files.
Work in the model.
Keep the familiar grid and familiar formulas, but attach assumptions, outputs, evidence, formulas, and reasoning to the model itself.
The spreadsheet stays familiar. The context becomes durable.
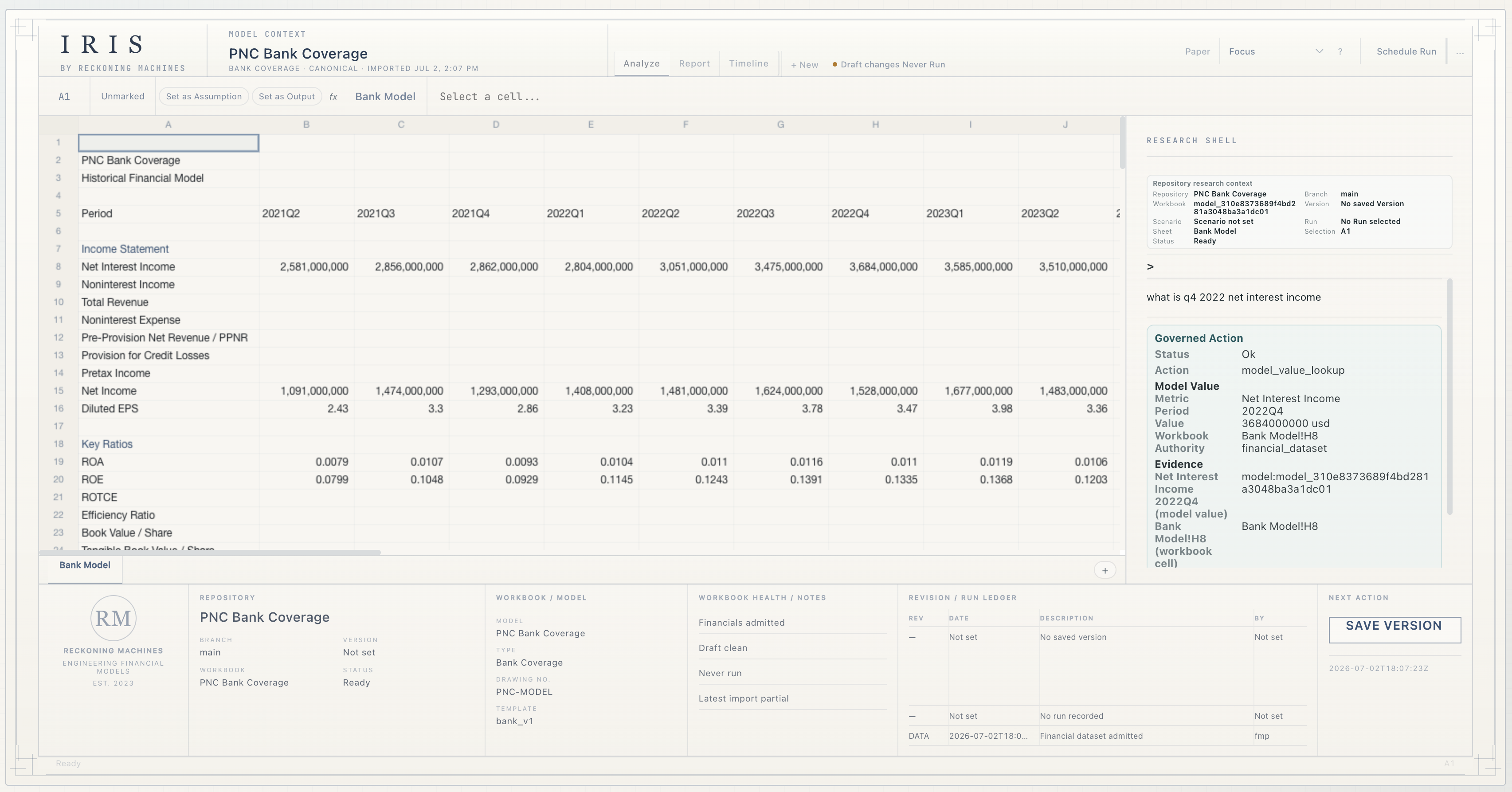
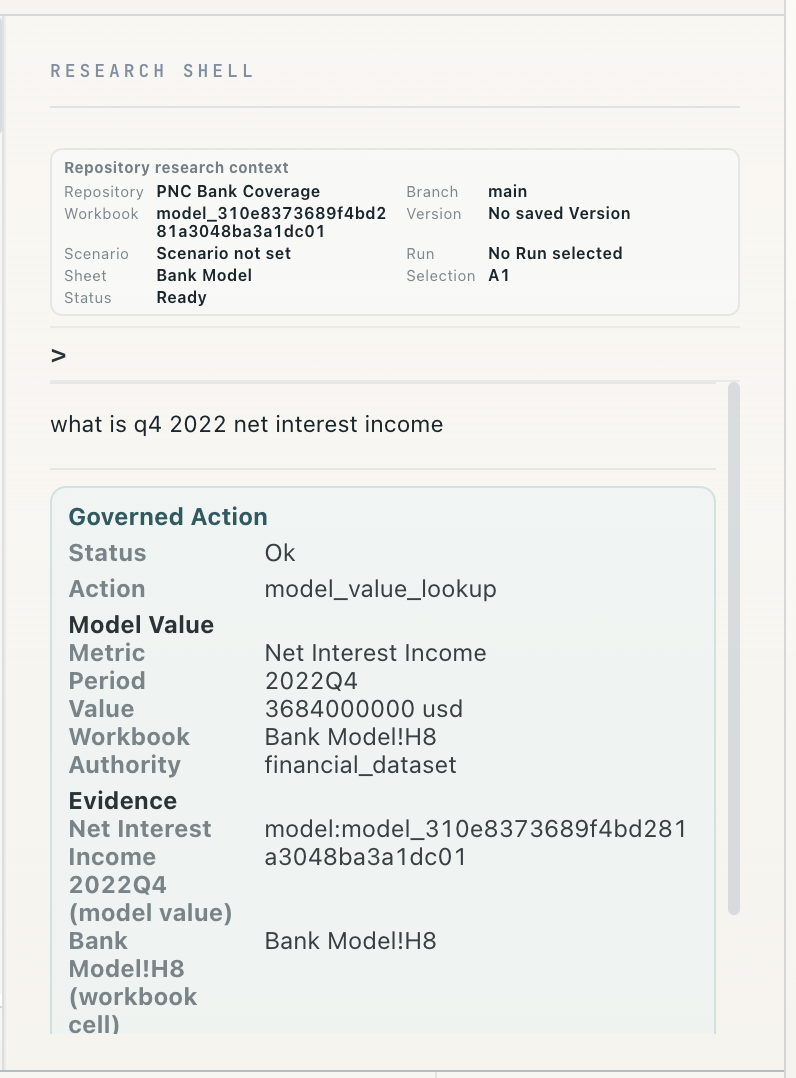
Ask the model.
Research Shell is the analyst interface to the repository.
- Why?
- What changed?
- What stands out?
- Have we believed this before?
- Remember this.
- What if margin were 5%?
- Write the report.
Ask questions. Run research. Test scenarios. Build memory.
Meeting Mode puts IRIS on your phone. You don't need Excel to understand a model. You need the repository.
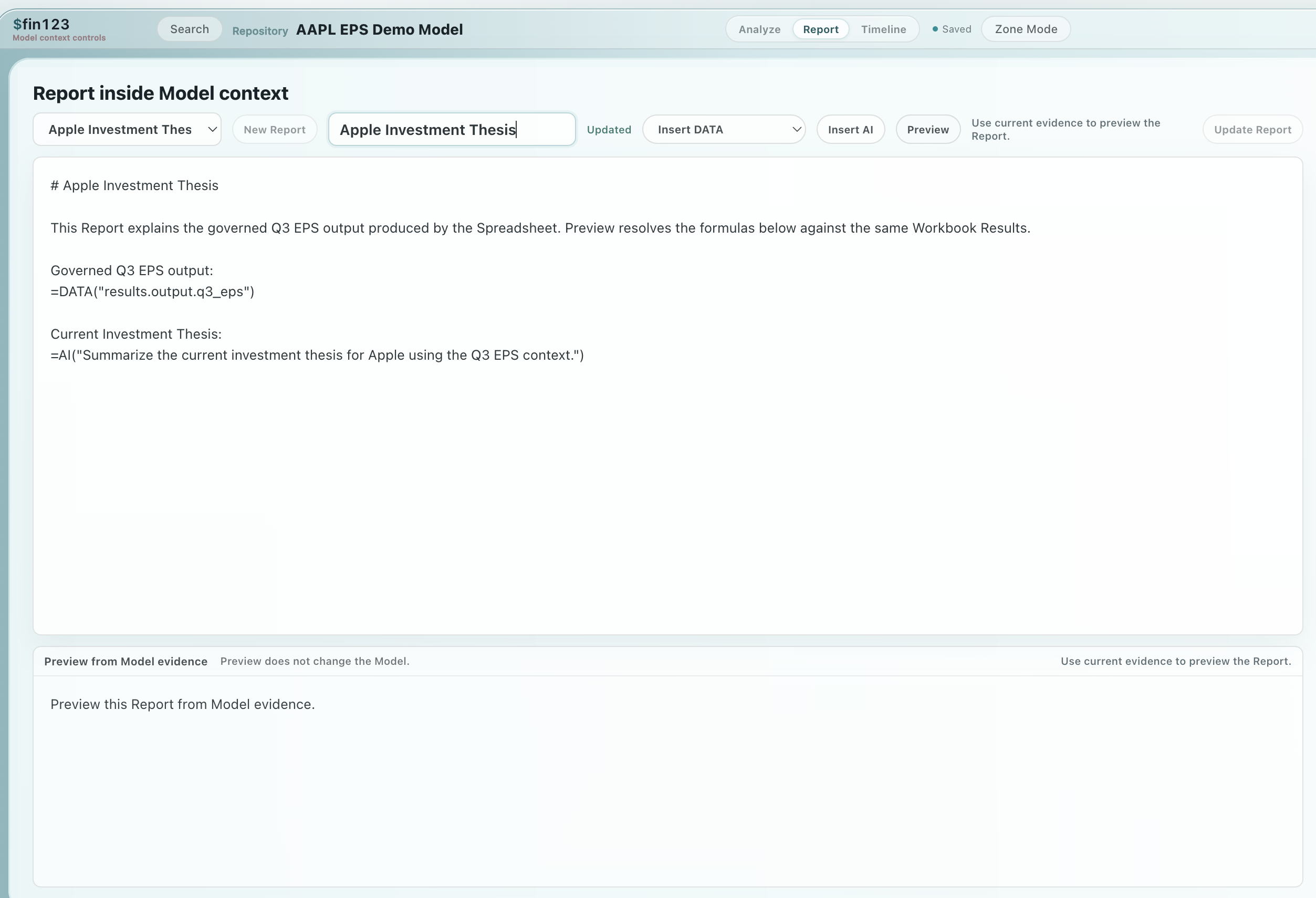
Turn work into communication.
Reports are emitted from model work. The explanation stays attached to the assumptions, outputs, evidence, and changes that produced it.
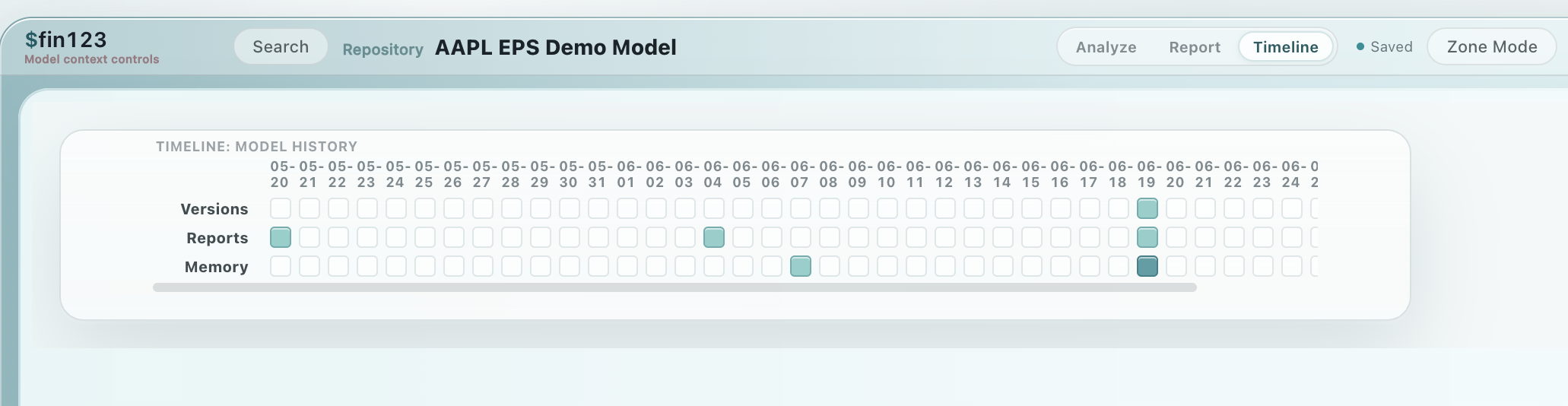
Preserve what changed.
The timeline keeps institutional memory: what changed, when it changed, and why it mattered. Every decision becomes part of the model's history.
Learns the Work.
Most software stores information.
IRIS learns from the durable investment work your organization chooses to create.
- Not by watching clicks.
- Not by profiling analysts.
- By learning from governed outputs.
- Every model.
- Every report.
- Every explanation.
- Every decision.
Every governed model, report, explanation, and decision strengthens the repository's understanding of your investment process.
That understanding compounds.
- Great Workspace
- Daily Work
- Governed Context
- Learns the Work
- Remembers
- Prepares
- Finds Things Worth Your Attention
- Better Decisions
- More Daily Work
Most software gets better when the vendor ships an update.
IRIS improves the more you use it.
The more governed models, reports, explanations, and decisions your organization creates, the better IRIS understands your investment process, prepares future work, preserves institutional knowledge, and helps analysts focus on what matters.
Serious research teams move faster when the model remembers.
One repository.
One timeline.
One Research Shell.
One model.
Everything stays connected.